
在科研、教育和信息管理等场景中,文档解析一直是一个极具挑战性的方向。尤其是面对包含复杂排版、公式、图表、化学结构甚至手写笔迹的学术论文或科研资料时,传统的多阶段 OCR+NLP 流程往往显得笨重且不够精准。
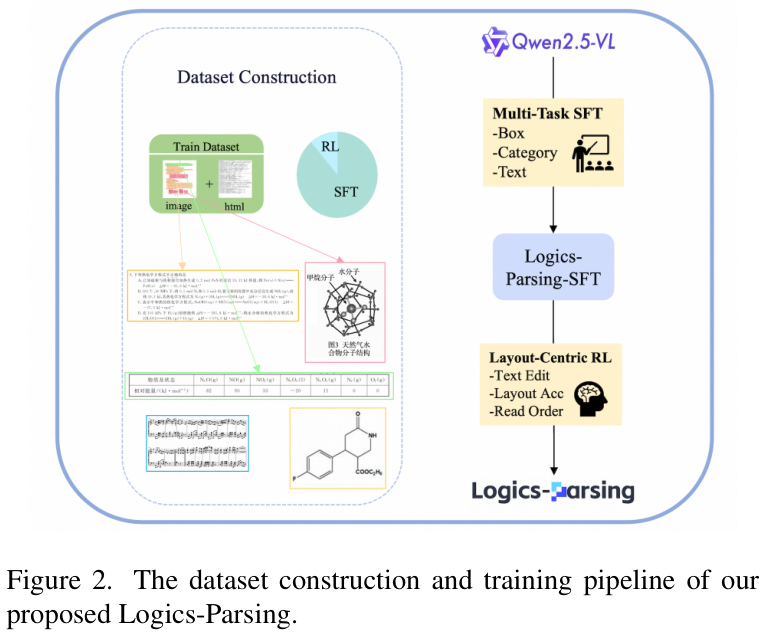
而阿里开源的 Logics-Parsing,为这类复杂文档解析任务带来了一种全新的端到端解决方案。它基于视觉语言模型(Vision-Language Model, VLM),通过监督微调与强化学习相结合的方式,直接从文档图像中生成结构化的 HTML 结果,让“理解文档”这件事变得更智能、更彻底。
一步到位:从图片到结构化 HTML
Logics-Parsing 最大的亮点在于其“一步到位的端到端解析”能力。
传统方案往往要经过文字检测、文字识别、版面分析、内容分类等多个独立阶段,每一步都可能引入误差。而 Logics-Parsing 则直接输入文档图片,输出结构化 HTML:
解析结果不仅包含段落、标题、表格、图片、公式等逻辑块的层次结构,还保留了位置信息和语义关系。这意味着你不仅能还原页面布局,还能对内容进行进一步分析或重组。

精准识别:难点内容也不在话下
科学文献解析的难点往往集中在以下几类内容:
-
复杂数学公式:多行排列、嵌套符号、上下标混排;
-
化学结构图:分子结构图与化学符号混合;
-
手写笔记或批注:非标准字体、模糊边界;
-
混合排版文档:图文表并列、跨页元素。
Logics-Parsing 借助视觉语言模型的多模态理解能力,能够在单一模型中统一解析这些复杂内容。
值得一提的是,它甚至能自动识别化学结构图并导出对应的 SMILES 格式,这对于化学、生物等学科的科研资料管理非常有价值。


干净的输出:结构化且语义清晰
Logics-Parsing 输出的 HTML 不仅结构清晰,还自动过滤页眉、页脚、页码等冗余信息,聚焦文档核心内容。
最终结果兼具:
-
可视化还原度高:忠实反映文档布局;
-
逻辑结构明确:方便机器读取和再加工;
-
轻量化:HTML 输出简洁、可直接嵌入下游系统。
这让它非常适合用于科研知识库建设、数字化档案整理、文档搜索引擎等应用场景。
实力验证:自研基准测试表现领先
根据阿里团队发布的介绍,Logics-Parsing 在自研的复杂文档解析基准测试中,显著超越了传统 OCR+结构化解析流水线模型。
无论是文字识别准确率、公式识别精度,还是整体 HTML 结构还原度,都有明显优势。
这一成果不仅展示了阿里在视觉语言模型上的研发深度,也预示着**文档解析正在从“规则驱动”迈向“智能理解”**的新阶段。
应用前景:科研、教育与信息智能化的加速器
Logics-Parsing 的应用潜力十分广泛,尤其在以下领域表现突出:
-
🧪 科研文献:自动提取论文公式、图表、参考文献等信息;
-
⚗️ 化学与生物资料:解析结构图、生成 SMILES 或分子式;
-
✍️ 手写笔记:数字化整理学术或教学笔记;
-
📚 教育与出版:智能化内容重排与知识结构提取;
-
🔍 搜索与问答系统:基于解析结果进行精准内容检索。
随着 VLM 技术的不断进步,这类“端到端文档理解系统”将成为科研与知识管理的基础工具。
项目地址与体验
项目开源地址:
👉 https://github.com/alibaba/Logics-Parsing
项目已提供模型权重与示例,可直接体验从图片到结构化 HTML 的完整流程。
本文地址:https://www.navagpt.com/?p=2096&preview=true
© 版权声明
- 转载时请保留原文链接,谢谢!
- 本站所有资源文章均来源于互联网的收集与整理,本站并未参与制作。若侵犯了您的合法权益,请联系我们将及时删除。
- 本站发布的资源来源于互联网,可能包含水印或引流等信息,请用户擦亮双眼,自行辨别,做一个有主见、具备判断力的使用者。
- 本站资源仅限于研究和学习交流使用。如需用于商业目的,请务必购买正版授权,否则由此产生的一切后果将由使用者自行承担。
- 联系方式(#替换成@):navagpt#qq.com

扫描二维码下载APP
相关文章



暂无评论...